 ai论文查重
ai论文查重今天为大家介绍的是来自Zhiyong Lu团队的一篇论文。生物医学研究产生了大量信息,其中许多信息只能通过文献获取。因此,文献搜索对于医疗保健和生物医学至关重要。最近在人工智能(AI)方面的进步已经扩展了该功能,不再局限于关键词搜索,但这些进步可能对临床医生和研究人员来说不太熟悉。
在生物医学领域,文献是传播新发现和知识的主要手段。大量通过生物医学研究积累的信息只能通过文献访问。因此,文献搜索——检索科学文章以满足特定信息需求的过程——对所有生物医学研究和病人护理的方面都很重要。然而,生物医学文献的指数级增长使得识别相关信息变得具有挑战性。PubMed,最广泛使用的生物医学文献搜索引擎,目前包含超过3600万篇文章,每年新增超过100万篇。一个典型的PubMed查询会检索到数百到数千篇文章,然而,超过前20个结果的文章中,不到20%的文章被审阅。这促使PubMed从基于最新性的排名转向基于相关性的排名,以更好地优先考虑最相关和最重要的文章。PubMed主要作为一个通用的生物医学文献搜索引擎。尽管在过去几十年中有了显著改进,但PubMed主要接收用户的短关键词查询,并返回一系列未经进一步分析的原始文章。因此,它可能无法最佳地服务于需要替代查询类型或对文章排名有特定要求的专业化信息需求。
虽然在过去二十年中提出了各种基于网络的文献搜索工具来补充PubMed针对特定文献搜索需求,但它们仍然未被充分利用且对临床医生和研究人员来说不太熟悉。综述文章旨在使读者熟悉可用的工具,讨论最佳实践,识别不同搜索场景的功能差距,并最终促进生物医学文献的检索。表1列出了本文介绍的基于网络的文献搜索工具,按它们满足的独特信息需求分类。具体来说,文献搜索工具被组织成五个领域:(1)循证医学(EBM),用于识别高质量的临床证据;(2)精准医学(PM)和基因组学,用于检索与基因或变异相关的信息;(3)语义搜索,用于查找与输入查询语义相关的文本单元;(4)文献推荐,用于建议相关文章;以及(5)文献挖掘,用于提取文献中的生物医学概念及其关系以进行基于文献的发现。图1展示了搜索场景的高层次概览。针对不同信息需求的搜索工具在它们接受的查询类型、处理文章并将其与输入查询匹配的方法,以及如何向用户展示搜索结果方面有所不同。
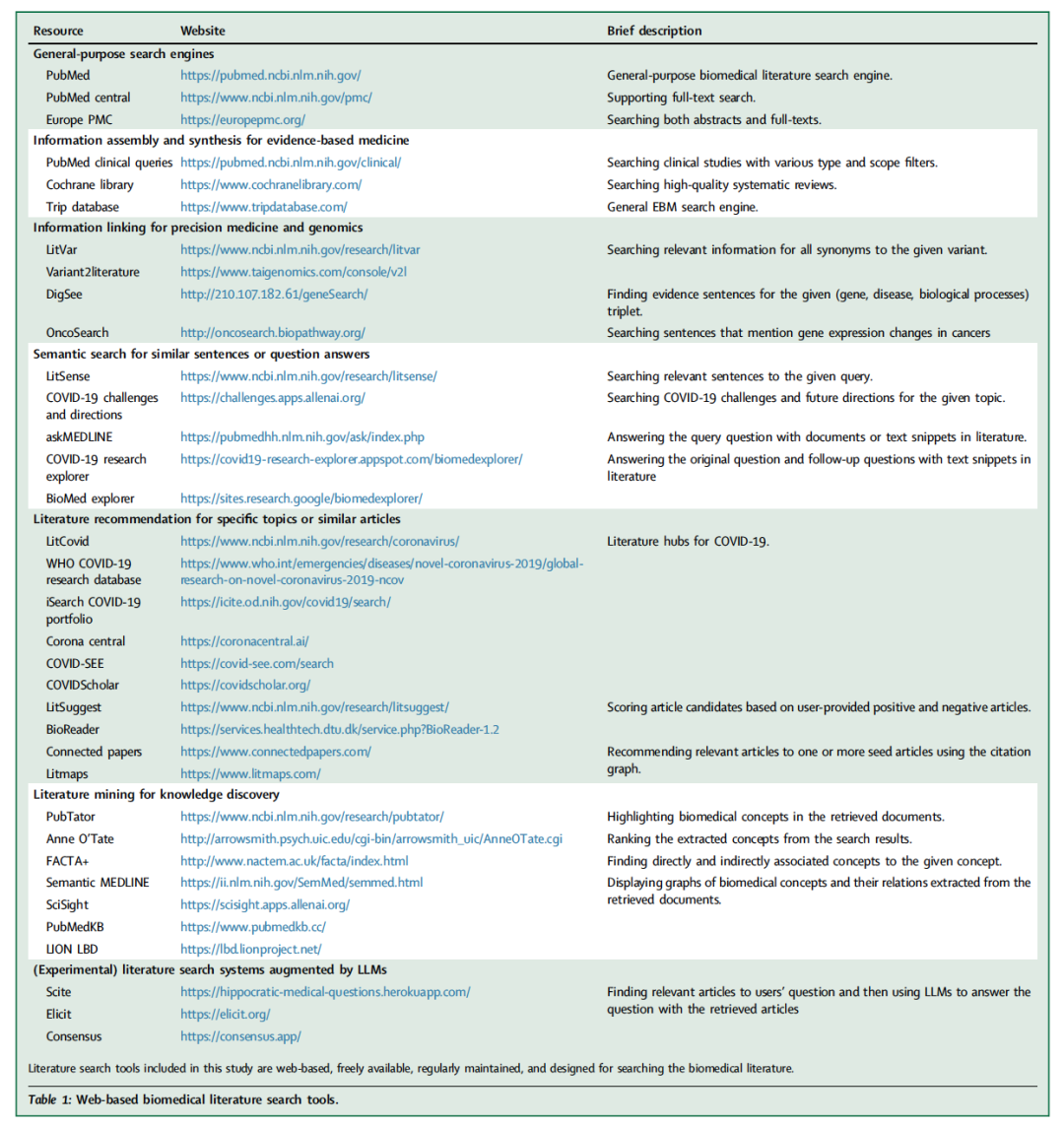
表 1
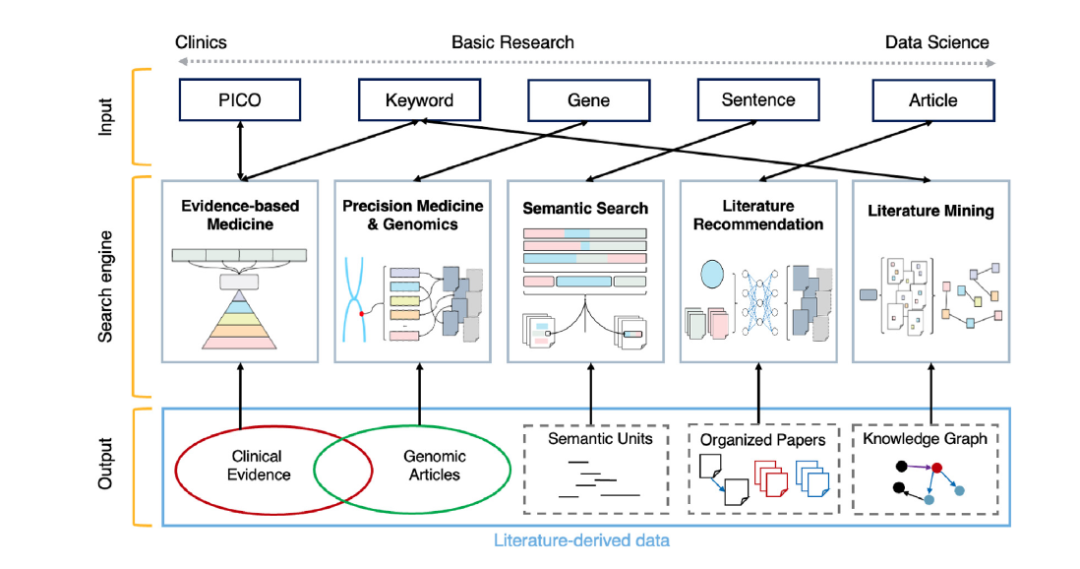
图 1
PubMed
PubMed由美国国家医学图书馆开发和维护。2021年,它平均每天处理大约250万次查询。PubMed搜索引擎在每篇文章的索引字段中寻找用户查询的精确匹配项,包括标题、摘要、作者列表、关键词和MeSH术语。传统上,所有匹配的文章都以倒序时间顺序返回。2017年,引入了一种新的基于AI的排名模型——最佳匹配(Best Match),以通过返回最顶部的最相关文章来更好地协助用户。除了生物医学主题的相关性搜索,PubMed还支持各种其他搜索功能。这些包括通过标题和期刊名称等参考文献信息匹配单一引文,以及在进行系统性综述时通常使用的布尔运算符。由于PubMed不索引全文文章,那些在全文中与查询匹配但在摘要或标题中不匹配的文章将不会被检索。这种查询由PubMed Central(PMC)容纳,它提供了超过900万篇免费可用的全文文章。不幸的是,PMC不支持搜索其他2700万篇缺乏全文可用的PubMed文章。欧洲PMC(Europe PMC),作为PMC的合作伙伴,截至2023年7月,包含4270万篇摘要和900万篇全文文章。对于三种类型的文献搜索实践,PubMed应该是首选:(1)通过关键词查询探索生物医学主题,如“糖尿病治疗”,借助PMC在全文中进行关键词搜索(当可用时);(2)使用文章标题、作者或PubMed ID搜索单一引文;(3)使用布尔查询进行可复制的文献筛选。
信息整合用于循证医学
循证医学(EBM)要求临床医生遵循高质量证据,这些证据主要来自临床研究的同行评审文章。高效检索这些证据对于实施EBM至关重要。因此,应有效地构造临床问题,至少包括”PICO”元素(人群、干预措施、对比和结果)。例如,在“Remdesivir是否降低了COVID-19患者与安慰剂相比的住院死亡率?”中,PICO元素分别是COVID-19(人群),remdesivir(干预措施),安慰剂(对比)和住院死亡率(结果)。EBM搜索引擎应能够处理PICO和自然语言临床问题。临床证据涵盖了广泛的文献,其质量具有显著的变异性。例如,系统评审通常被认为是比随机对照试验(RCTs)更高质量的证据,而RCTs则比个案报告代表更高质量的证据。因此,理想的EBM搜索引擎(图2)应考虑证据质量来过滤或排列文章。理想的EBM搜索引擎架构允许PICO风格的输入,并根据证据质量对结果进行排名。
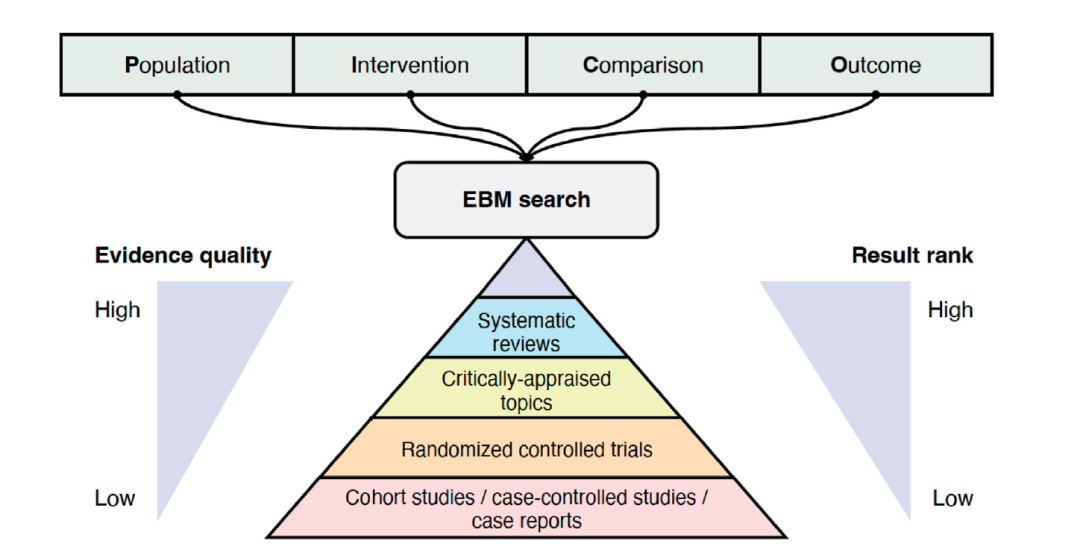
图 2
接受PICO查询的系统
一些EBM搜索引擎,如Trip数据库、Cochrane PICO搜索和Embase,容纳基于PICO的查询。这些系统的搜索界面通常包含四个主要PICO元素对应的文本框。一般而言,这些系统提供更精确的结果,因为搜索意图在查询中被明确说明。例如,将“糖尿病”作为“人群”项输入,EBM搜索引擎只返回关于糖尿病患者的临床研究。与此相反,基于关键词的搜索引擎将返回任何提到“糖尿病”的文章,无论其与患者研究的相关性如何。
带过滤检索结果的系统
PubMed临床查询搜索采用预定义的过滤器,用于各种类型的临床研究,如治疗和诊断。用户还可以为过滤器选择宽泛或狭窄的范围。临床医生应使用狭窄范围快速概览关键研究,而进行证据综合的研究人员应使用宽泛范围进行全面搜索。一些EBM搜索引擎优先检索次级证据,如通常具有更高质量的系统评审。一个值得注意的例子是Cochrane数据库,它收录了超过11000个高质量的系统评审和协议。精心评估的主题总结了特定主题的证据,如2型糖尿病的预防,使用简短、模板化的标题简化检索。因此,它们提供了临床决策指导的现场证据。
协助证据合成
与证据检索相比,较少的系统促进证据合成,后者指的是系统地收集、分析和组合多项研究结果,以对特定问题或主题得出全面结论。证据合成在系统评审过程中发挥着至关重要的作用。然而,进行系统评审的用户需要手动筛选所有相关文献以无偏见地解决临床问题,这是一个极其耗时的过程,因为可能有大量的文章跨多个数据库相关。尽管努力使用机器学习自动化这一筛选过程,但这些功能由于这项任务的内在复杂性和对错误的低容忍度而尚未整合到基于网络的EBM搜索引擎中。
精准医学和基因组学的信息链接
精准医学(PM)是一种新兴的方法,它根据个体在基因、环境和生活方式上的差异来定制疾病治疗和预防措施。高通量测序技术的快速发展导致获取个体基因组数据的成本大幅下降。人类基因组因其高度异质性,包含大量的基因组变异。理解这些基因组变异的生物学功能和临床意义对于精准医学的进步至关重要。这类信息通常存储在手动整理的数据库中,如UniProt、dbSNP和ClinVar。这些数据库手动总结并维护文献中每个数据条目的初步发现。然而,生物医学文献的增长,平均每天新增3000篇文章,超出了手动整理的速度,留下了知识空白。为了补充这些数据库,需要能够直接从原始文献中提取与基因或变异相关信息的搜索引擎。本节主要讨论此类系统。对于精准医学和基因组学搜索引擎来说,一个重大挑战是同一变异有多种表述方式。例如,变异“V600E”也可能被称为“1799T > A”或“rs113488022”。这种同义性为基于关键词的搜索引擎带来了检索挑战。为此,许多专门的文献检索工具被提出;它们的核心功能如图3所示,搜索引擎应能检索到提及确切变异查询及其同义词的所有文章。
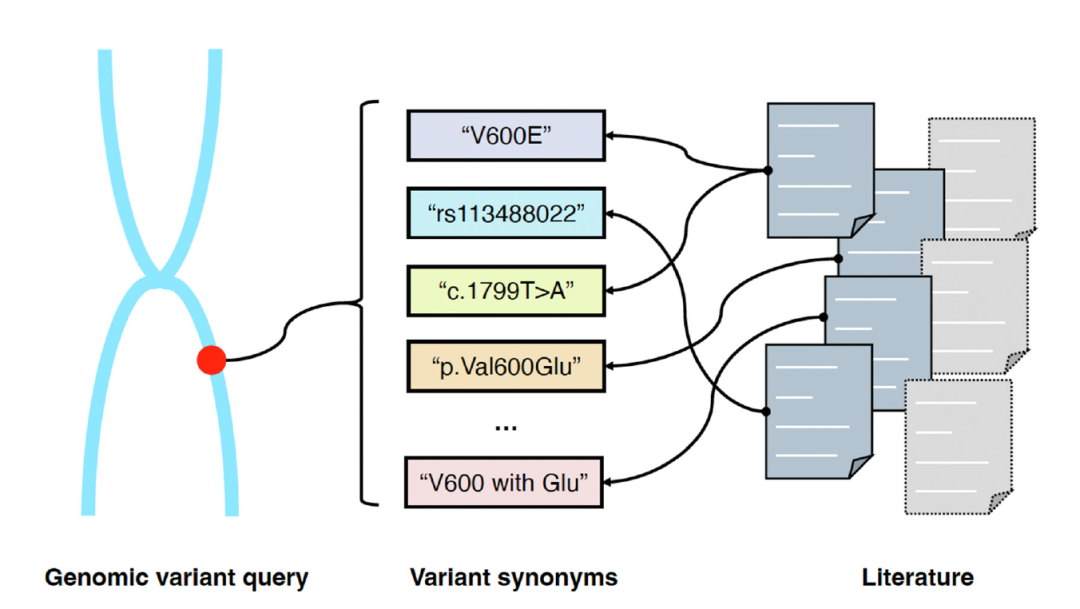
图 3
识别同义词
一些工具,如LitVar,专注于文献中变异同义词的规范化。LitVar使用文本挖掘工具tmVar来识别变异名称并将其转换为标准形式。LitVar索引了来自PubMed的摘要和来自PubMed Central的全文,并定期更新,以确保检索到包含查询同义词的所有当前文献。另一个工具variant2literature提供了一个结构化查询界面,允许用户指定染色体位置。variant2literature的独特之处在于它能够从文章的文本以外,还从图表中提取变异信息。
链接基因和其他信息
有些系统不仅识别基因的同义词,还探索与基因组相关的信息。DigSee接受基因、疾病和生物过程的三元组作为输入,并在PubMed摘要中找到将基因通过给定生物过程与疾病链接起来的句子。OncoSearch专注于检索基因表达变化和癌症进展状态的文献证据。具体而言,它标注文献中的句子,指示输入基因是上调还是下调,表达变化与癌症进展或退化的关系,以及基因在癌症中的预期作用。
结论

图 4
与寻找输入查询的精确匹配的基于关键词的搜索不同,语义搜索定位与查询在语义上相关的文本。例如,“renal”和“kidney”在语义上非常相似。图4概述了语义搜索,其中返回与查询在语义上匹配的文本单元,如句子,这些句子提到了相同的疾病并讨论了可能的治疗方法。这些文本不一定包含确切的查询术语,使得它们不太可能被传统文献搜索引擎检索到。
相似句子搜索
针对文章级别的搜索经常忽视句子中的更细粒度信息。句子级别的搜索对于精确知识检索很重要。例如,可以搜索一个特定的发现,并将其与其他文章中的相关发现进行比较。LitSense是一个基于Web的系统,用于从PubMed和PMC检索句子,通过上下文推断单词的表示来匹配文本的语义。LitSense的结果可以按部分过滤。虽然LitSense搜索所有类型的相似句子,但也提出了几种文献搜索引擎,用于更特定类型的句子。
问答
生物医学查询经常自然地表达为问题,如EBM中基于PICO的临床问题。然而,传统的基于关键词的搜索引擎可能无法有效处理自然语言问题,因为问题和答案往往缺乏高度的词汇重叠。生物医学问答(QA)是一个活跃的研究领域,但用户友好的Web工具仍然稀缺。askMEDLINE系统从PubMed PICO搜索演化而来,允许直接输入临床问题,例如,“用自来水冲洗是否是清洁简单撕裂伤后缝合的有效方法?”。askMEDLINE显示结果为一系列相关文章。COVID-19 Research Explorer和BioMed Explorer是由Google AI开发的生物医学文献实验性语义搜索引擎。前者专注于COVID-19文章,后者涵盖所有PubMed文章。用户提出自然语言问题,答案在结果中的文本片段中突出显示。
特定主题或相似文章的文献推荐
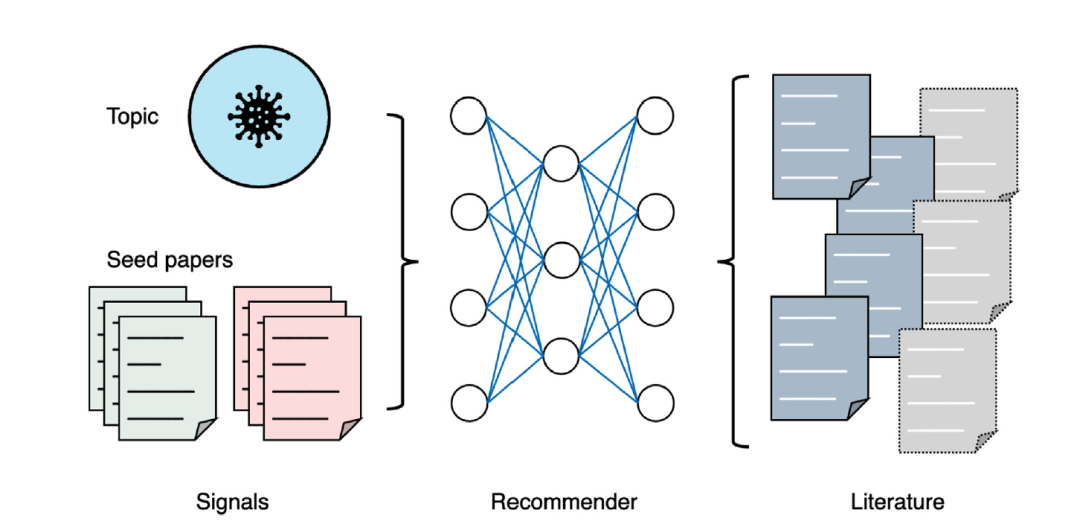
图 5
生物医学研究常常需要全面探索相关文献。由于难以构造查询来全面捕获所有相关工作,传统的基于关键词的搜索引擎通常在这方面效率不高。文献推荐引擎允许用户探索与特定研究主题相关或与已知相关的一系列文章相似的文章。作者主要介绍两种类型的文献推荐工具:基于主题和基于文章的,如图5所示。
基于主题的文献推荐系统通常是为选定的研究主题量身定制的数据库或文献中心,例如COVID-19大流行。由于最初缺乏SARS-CoV-2和COVID-19的标准术语,出版物使用了多种术语,这使得通过基于关键词或布尔搜索来识别相关文章变得复杂。LitCovid是一个策划的文献中心,包含来自PubMed的与COVID-19相关的文章,它按八个广泛主题组织,包括机制、传播、诊断和治疗。另一方面,基于文章的文献推荐系统生成与初始(种子)文章相关的文章列表。现代文献搜索引擎通常提供与单个文章相关的文章列表,如PubMed中的“相似文章”部分。然而,已经提出了一些系统,支持识别与一系列文章而不是单个文章相关的文章。LitSuggest是一个基于机器学习的文献推荐系统,它根据候选文章与用户提供的正面文章列表的相似度以及与可选的负面文章列表的不相似度进行评分。用户还可以通过对得分的候选文章子集进行注释并重新训练推荐模型来提供人在循环中的反馈。
文献挖掘用于知识发现
图 6
文献挖掘旨在帮助用户通过自然语言处理(NLP)技术从科学出版物中发现新见解。这些技术包括命名实体识别(NER),即识别基因和疾病等生物医学概念的任务,以及关系提取(RE),即对识别出的概念之间的关系进行分类。例如,NER工具可以在句子中识别遗传变异和疾病名称,RE工具可能将它们的关系分类为突变引起的疾病。提取出的概念及其关系可以组织成图,称为知识图谱,这种图谱结构性地总结了与给定查询相关出版物中编码的知识。通过展示知识图谱,文献搜索引擎为用户提供了发现的知识概览,从而通过预测潜在的缺失链接促进新知识的发现。这一过程在图6中可视化展示。
实体增强搜索
一些文献搜索引擎通过生物医学概念增强检索结果。PubTator突出显示了由最先进NER工具识别的六种类型的概念,如基因和疾病。PubTator还通过批量下载和应用程序编程接口公开其注释,允许其他搜索引擎用PubTator概念增强搜索结果。值得注意的是,PubTator已被集成到LitVar、LitSense和LitCovid等平台中。Anne O’Tate提供了排名概念的选项,如重要单词、重要短语、主题、作者、MeSH对等,这些都是从检索到的文章中提取的。
关系增强搜索
一些系统进一步处理提取的概念,并使用相关概念展示搜索结果。FACTA+找到与给定概念相关的概念及支持句子,并可以通过某些类型的“枢纽概念”作为桥梁发现间接相关的概念。Semantic MEDLINE从检索到的文章中提取谓词,这包括两个生物医学概念和一个关系,并提供谓词的图形可视化。SciSight是一个针对COVID-19的探索性搜索系统,可以展示与给定概念相关的生物医学概念图。PubMedKB提取和可视化变异、基因、疾病和化学品之间的语义关系,提供了一个带有交互式语义图的用户界面用于输入查询。尽管已提出许多自动构建生物医学知识图谱的系统,但它们的实用性仍待在未来的研究中确认。
编译 | 曾全晨
审稿 | 王建民
参考资料
Jin, Q., Leaman, R., & Lu, Z. (2024). PubMed and beyond: biomedical literature search in the age of artificial intelligence. Ebiomedicine, 100.
