 ai论文查重
ai论文查重
在今天,人工智能(Artificial Intelligence,AI)的火爆,催化了各种行业与AI的联姻趋势,学术界也一样。
去年9月,Nature刊登了一篇关于AI如何在科学文献中的应用文章。该文中,伦敦的艾伦·图灵研究所的数据科学家Giovanni Colavizza说,传统工具(PubMed、Google Scholar等)在很大程度上扮演了文献索引的角色,但基于AI的工具可以提供更为透彻的文献资料。

更为透彻的文献资料?这个就得说到文献阅读目的了。AI算法通常可以构造“知识图”,详细描述所提取实体之间的关系并将其显示给用户。例如,如果在同一句子中提到对象甲和对象乙,则可能暗示它们是相关的。如Colavizza说:“知识图将其编码为数据库中的显式关系,而不仅仅是文档中的句子,从本质上使它可以机读。”
即是说不再是单纯的文字搜索与提取,而是让AI理解文献的信息,并可视化地呈现出给我们,如来自德国海德堡的欧洲分子生物学组织(EMBO)的SourceData,专注于解读文献中的实验结果图。为此,笔者今天给大伙分享一款可以搜索存在特定关系的实验结果图的AI平台,SourceData。
它的优势在哪呢?好比我们去搜索胰岛素如何调控葡糖糖,得到往往是某个名词的百科或者某篇文献的索引。
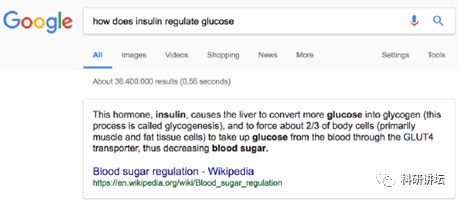
但在SourceData上,则可以搜出关于胰岛素如何调控葡糖糖的实验数据图片,链接文献等支持这个特定关系的科学数据。
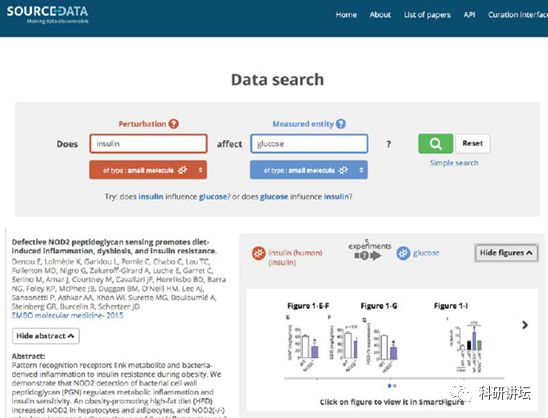
对于X是否影响Y,倘若有这么多的科学数据支持,那么,它的这个关系的可信度就大增了。当然,最后还是离不开实验。
一、SourceData
SourceData(https://sourcedata.embo.org/)是EMBO出版社旗下的一个开放AI平台,以标准化的机器可读格式描述了科学文章中的图形内容,从而可直接搜索研究论文中的数据,允许使用其数据内容来搜索和链接文章。

2017年,由Swiss Institute of Bioinformatics、EMBO和EMBL-EBI三家欧洲有名的机构在Nature Methods联合发表的《SourceData: a semantic platform for curating and searching figures》,揭开了SourceData的神秘面纱——Make figure more discoverable。其主要是解决了出版过程中,每篇文献中的数据独立,且难于被搜索和聚合的问题。
SourceData成果的发布具备三大亮点:
1.促进浏览和发现文献中的数据;
2.将可发现性与数据可用性相结合;
3.在开放科学与科学出版之间架起桥梁。
同时,SourceData之所以混得开,也离不开三点:
1. EMBO出版社的全力支持

相信大伙也不陌生,EMBO旗下的杂志都是各自领域内的狠角色,IF均高于6,除了新办的Life Science Alliance还没有拿到影响因子。由EMBO Press出版的The EMBO Journal, EMBO Reports, Molecular Systems Biology和 EMBO Molecular Medicine将通过SourceData处理所有接受的手稿,即意味着SourceData可获取EMBO出版社旗下期刊的文献信息和全文,这给了SourceData可行的前提,拿到文献的全文。同样地,SourceData也正将更多可开放获取的期刊文献纳入进去,扩大数据库。
2. Open Science的浪潮
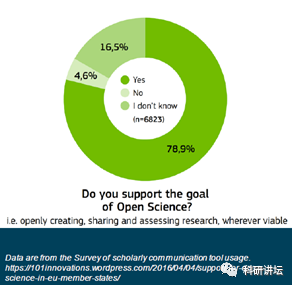
越来越多人支持的文献开放获取,Open Science似乎已成主流趋势,这也为SourceData获取大量文献全文铺了一些基础。
3. AI技术的日渐成熟
正如下面这一张文献图片,AI是如何将图片进行阅读的呢?
一般数据图,展示的是自变量X,在干预条件下,检测因变量Y,如下图。

再具体一点,则是以下。
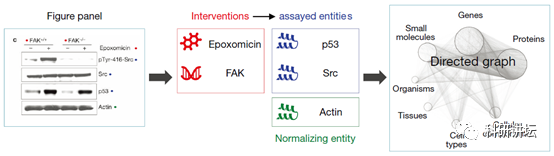
进而结合figure legend的文字,进行提取,关系匹配,结合人工批注,进而不断训练和修正,最后实现较为准确的实验图解读和供搜索。
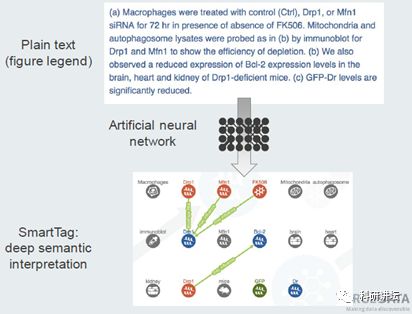
SourceData的负责人Thomas Lemberger说,SourceData目前处于早期阶段,已经生成了一个知识图,其中包括20,000个实验,这些实验是在编辑过程中人工手动整理的,涉及大约1,000篇文章。在线工具目前仅限于查询该数据集,但是Lemberger和他的同事正在使用它来训练机器学习算法,且不断扩大优质的数据集。
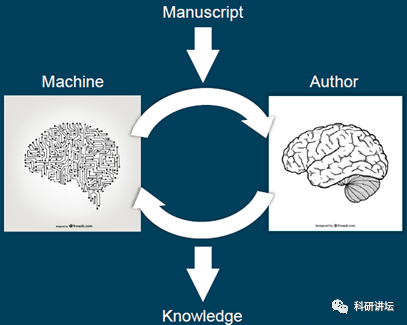
简单来说,SourceData所做的,正如下图所展示,人和AI联合,试图杀出由文献到产出知识的路。
也是因为这样,SourceData已被授予2018年的美国学术和专业协会出版商联合会(ALPSP)创新出版奖,ALPSP评委认可“该平台背后的高度策划和复杂发展及其对研究传播的意义”。
二、如何使用SourceData
首先,登上SourceData(https://sourcedata.embo.org)。
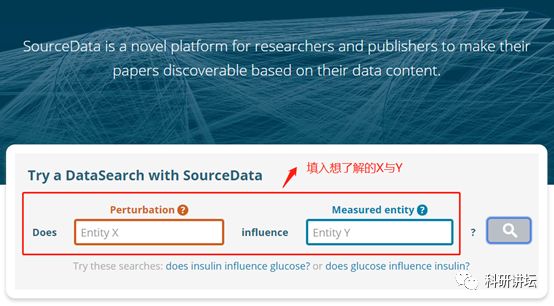
输入X与Y,即可进行搜索。但值得注意的是,目前还是处于早期阶段,数据资源还不是很全,可能支持某一个关系的更多文献数据没有被加进来。
如输入胰岛素与葡萄糖。
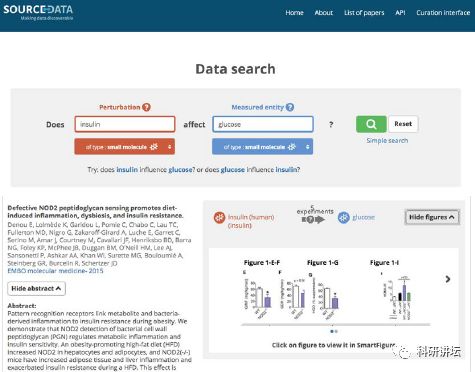
有关胰岛素与葡萄糖的文献数据图就会显示出来,以及所属文献。同时,还可进一步点击图片了解详情。

通过这样,则可以更加清楚支持数据的详情。此外,图片与EMBL-EBI的BioStudies数据库相连,与SourceData相辅相成。
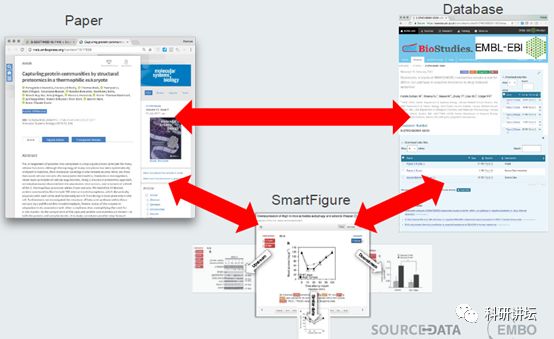
同时,参与该项目的还有学术出版界的NPG、Wiley等。

EMBO出版社主管Bernd Pulverer表示,与SourceData的合作是EMBO Press对数据完整性和透明性承诺的核心部分:“我们热烈地促进公平,准确和开放的数据,该政策鼓励在高质量的同行评审研究中共享可重复使用的数据文件。SourceData的这个试点项目使我们成为第一个提供完全集成的数据管理和加速发现的发行商,我们希望看到这种做法成为开放科学的出版标准。”
SourceData项目负责人Thomas Lemberger则说:“科学家们可以通过使其公开的数据可发现,可访问,可互操作和可被用来支持未来的研究。这被称为FAIR数据(https://en.wikipedia.org/wiki/FAIR_data)。SourceData提供了迄今为止FAIR原则最完整的实现之一。通过整理图形及其基础数据,SourceData为作者提供了一项服务,使他们的数据可搜索,互连,可访问和可下载,成为期刊出版物的组成部分。这个过程通过使人们能够相互交谈,基于实验数据在论文之间建立联系来增加价值。”
笔者认为,SourceData解决问题出发点的意义和前景都比较不错,故看好其会继续发展壮大,或许还会成为以后开放出版过程的一道程序。
相关阅读:
· 阿姨教你使用Reference编辑神器:EndNote
· 神器:不仅秒搜本地文件,还能1秒在线检索文献!
· 轻松5步搞定google学术搜索,让文献搜索和下载不再是烦恼
· 鼠标点2下,轻松将Pubmed文献保存到EndNote
· 干货:一个PubMed账号可以有这么多用处!
· 除了看文献,还有哪些可供参考?快来利用闲暇时间蓄电了!
· 干货:如何知道你找的文献可不可靠?



关注后获取《科研修炼手册》1、2、3、4、5、6、7、8、9、10
