 ai论文查重
ai论文查重开展一个新的课题前,往往需要对某个方向有深入的调研,这时候可以用如下方法快速完成文献调研及批量下载,以检索“Escherichia coli”细菌研究为例,具体如下:
第一步:进入AI based文献检索网站,输入关键词“Escherichia coli”,并点击批量下载,保存为Excel格式
https://www.citexs.com/Paperpicky?query=Escherichia%20coli&query1=&query2=&query3=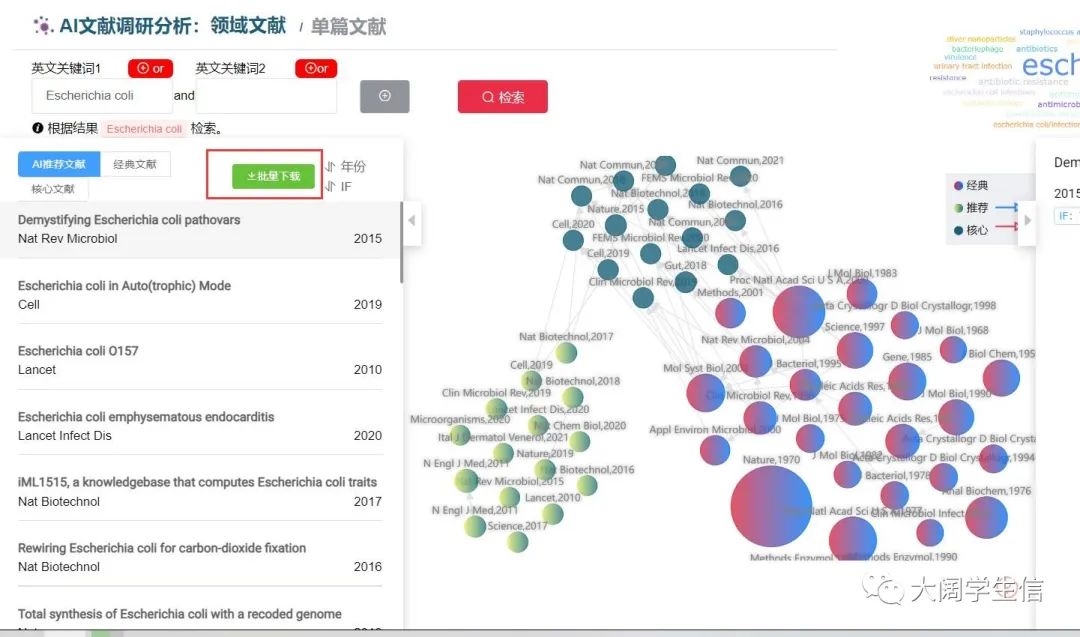
第二步:筛选影响因子>20以上的文献,选择标黄的doi号
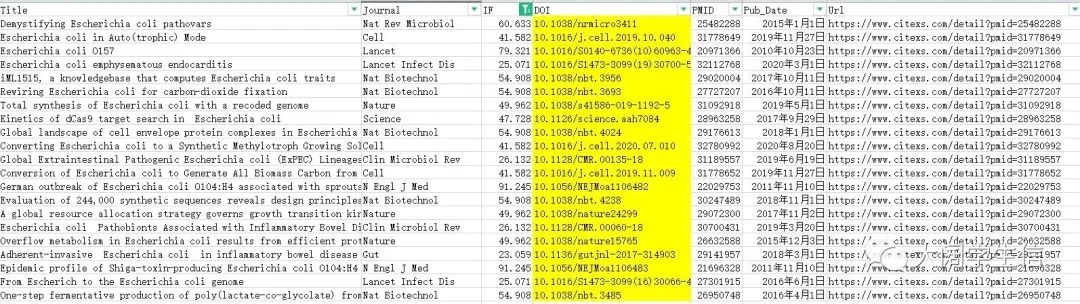
第三步:基于python爬虫代码,根据doi批量爬取文献
代码如下:
import requestsfrom bs4 import BeautifulSoupimport ospath="/xxxx/download_papter/result"if os.path.exists(path) == False:os.mkdir(path)f = open("doi.txt", "r", encoding="utf-8")head = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36'}for line in f.readlines():line = line[:-1]url = "https://www.sci-hub.ren/" + line + "#"try:download_url = ""r = requests.get(url, headers = head)r.raise_for_status()r.encoding = r.apparent_encodingsoup = BeautifulSoup(r.text, "html.parser")if soup.iframe == None:download_url = "https:" + soup.embed.attrs["src"]else:download_url = soup.iframe.attrs["src"]print(line + "t正在下载n下载链接为t" + download_url)download_r = requests.get(download_url, headers = head)download_r.raise_for_status()with open(path + line.replace("/","_") + ".pdf", "wb+") as temp:temp.write(download_r.content)except:with open("error.log", "a+") as error:error.write(line + "t下载失败!n")if "https://" in download_url:error.write(" 下载url链接为: " + download_url + "nn")else:download_url = ""print(line + "t文献下载成功.n")f.close()
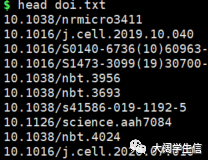
输入文件doi.txt
下载中~~~
