 ai论文查重
ai论文查重大家好,今天我们继续分享通用人工智能(AGI)技术的原创综述,该简短的综述将系统性地梳理目前的AGI发展状态和现状,并前沿性收纳最具有推动力的成果,可以作为该领域的入门参考资料。本分享将持续五期,本期主要讲述基于大模型的认知技术。
注:本文为PPT+讲稿形态,建议采用计算机而非手机显示观看,讲稿位于所解释的PPT的上方,有部分为个人观点,不够严谨之处敬请谅解。
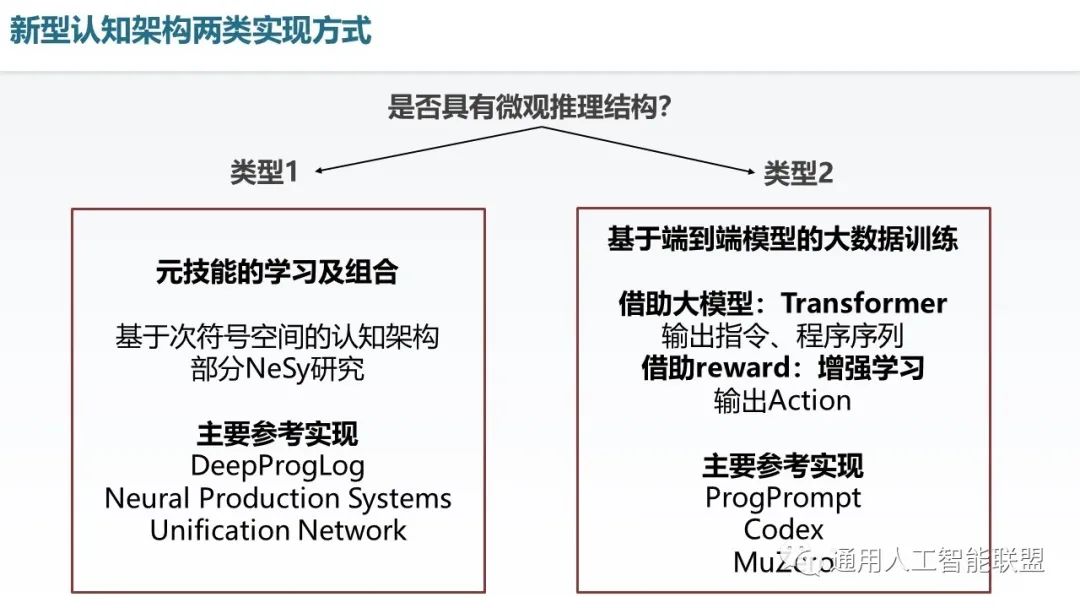
上面的讨论已经讲到我们的两类认知架构,在此在回忆一下,我们以是否具有微观结构,分成类型1和类型2。类型1是以元技能的学习及组合作为其特征,包括了次符号空间的认知架构的研究。以及部分neurosymbolic的研究。类型2即基于端到端模型的大数据训练,主要以transformer和增强学习作为典型案例。下面主要介绍类型2。
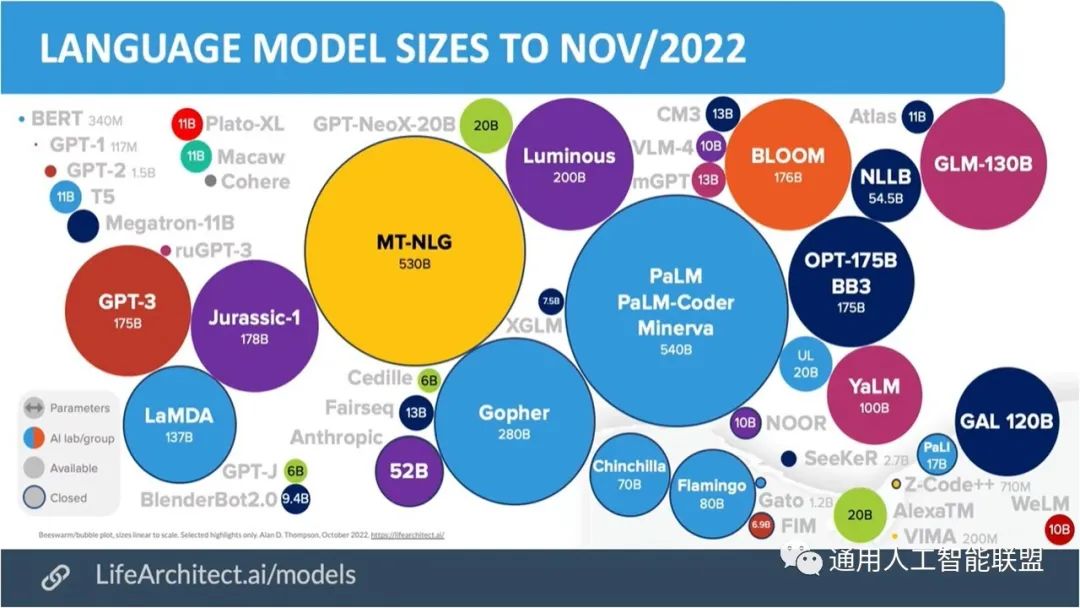
当前大语言模型进展非常迅速,已经具有下图所示的大量千亿及百亿级别的大模型。这些模型具有着明显的通用智能的潜在优势。
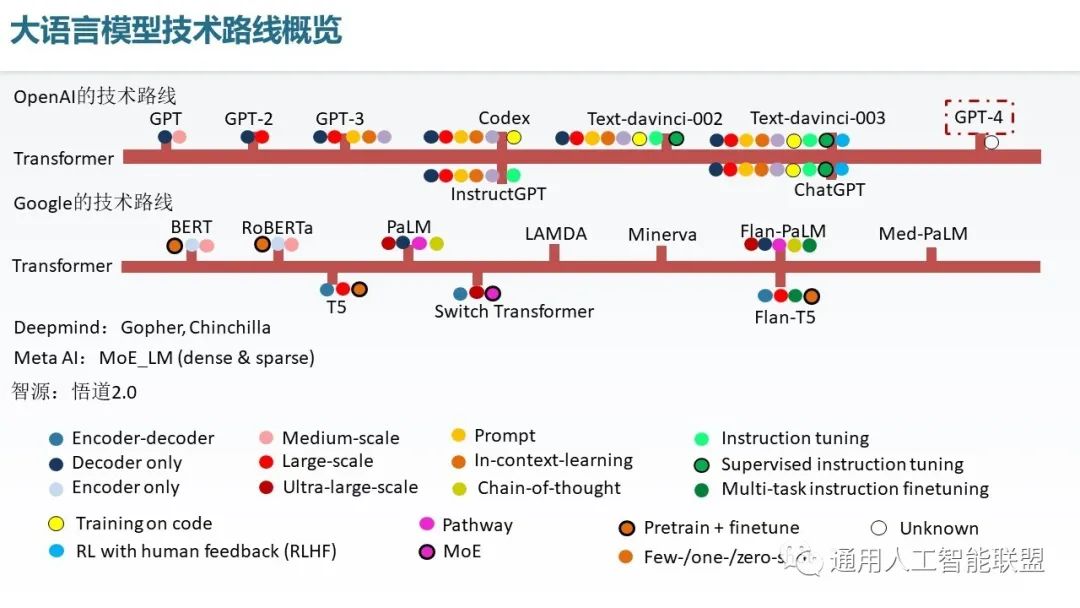
总体而言,现在具有两类主流技术路线。其中OpenAI一直秉承着生成式的技术路线。包括GPT3以及代码生成Codex。以及后续的一些演进GPT3.5版本。另一类是谷歌的BERT类基于掩码预测的大语言模型路线。后期谷歌也逐渐的多样化,形成了类OpenAI的生成式技术路线。DeepMind也具有着像Gopher、Chinchilla等大模型。Meta AI更关注多专家系统(MoE)构建的大模型。国内如智源也具有悟道2.0这样的一些超大规模的MoE模型,具有万亿参数。此外,我们可以认为其主要的技术特点包括如下几个方面,首先,都使用了Transformer,无论是Encoder only或Decoder only形态,还是Encoder-Decoder形态。其次具有着大规模或超大规模,即达到了百亿或千亿的参数级别。第三。在任务处理和调优方面,通常采用了提示(Prompt)方法。用于提升语言模型的任务通用性和小样本及零样本能力,In-context learning方法通过少量示例,让大语言模型进行推理期间的few shot学习,Chain of thought通过逐步思考提升了学习的精度,此外还有Instruction tuning实现了指令级别的提示,Tuning on code提升了大语言模型写代码的能力,RLHF提升了语言模型提供人类所需回答的这样一个能力,它是通过用Human feedback的样本,训练出一个评估模型,并基于评估模型进行大语言模型的进一步fine-tune实现。在实现结构上,有的模型具有Pathway或MoE的形态,通过多种类别的FFN,并进行当前案例的相似度评价,去选出少量的合适的专家子网络实现推理,以这种方式可以容纳更多参数,并实现任务的专有化。此外,模型从预训练加fine-tune的形态逐渐演化为Few-shot、One-shot和Zero-shot的形态。
(Meta AI [ref]: Efficient Large Scale Language Modeling with Mixtures of Experts)
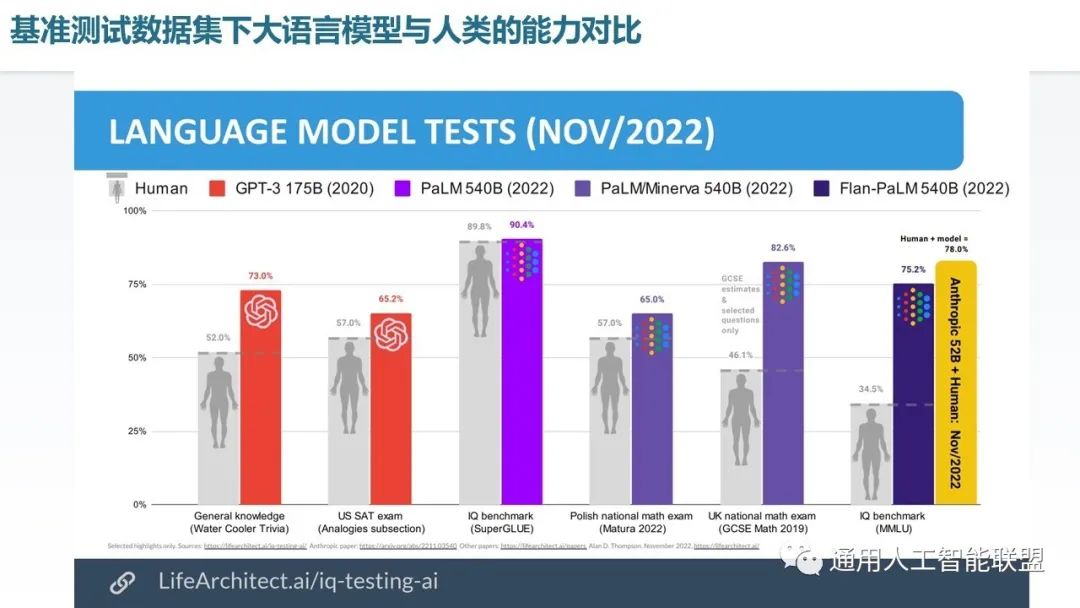
当前大语言模型在若干数据集上已经达到或超过了人类的平均水平。例如通用知识测试、一些考试、IQ Benchmark等等。
在大模型的常识多步逻辑推理上,Chain of Thought显著提升了模型的计算精度,在Big Benchmark Hard上可以实现大部分任务超越人类的表现,Big Benchmark Hard选择的是一些对于大模型而言比较难的一些问题,因此这也代表大量的自然语言处理任务的能力与人类已经接近或超过。此外,DIVERSE通过让模型输出多个解,并分析这些解的相似性,通过大部分解是正确解的投票机制,选出最优的解,从而进一步改善逻辑推理的性能。
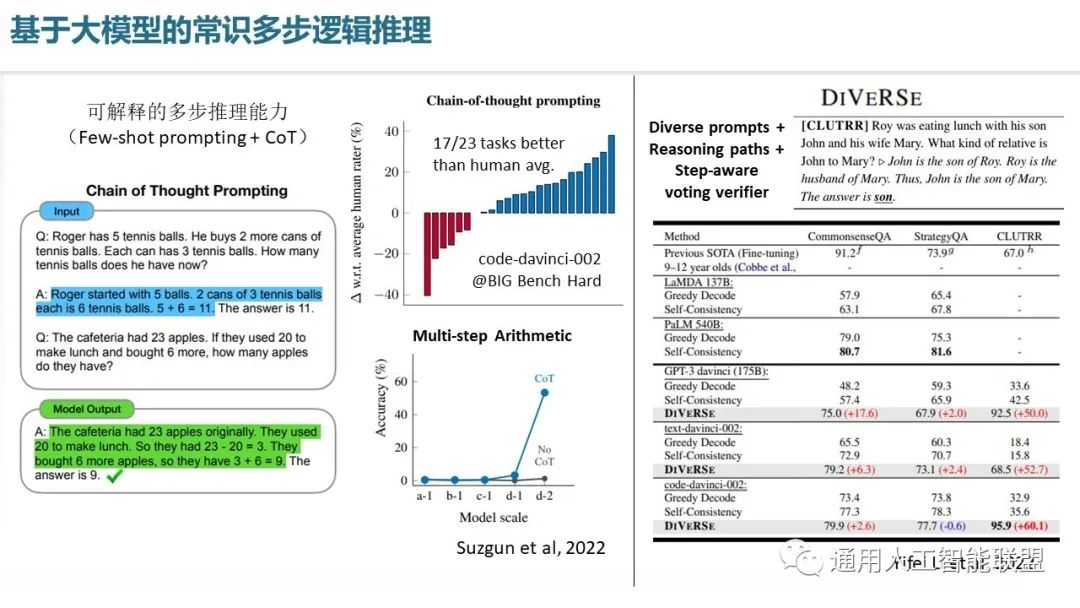
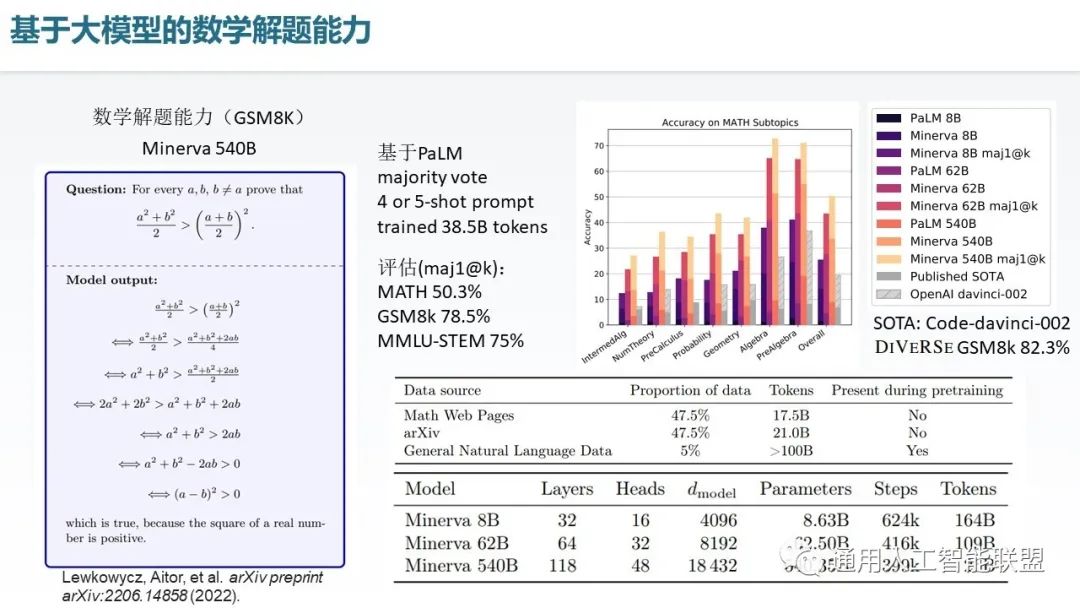
下面介绍基于大模型的数学解题能力,由于数学解题是逻辑思维里面最重要的,体现了智能水平和逻辑思维水平的一类问题,因此在数学解题能力上的成绩往往标志着当前的这些模型的一个核心的逻辑推理智能的水平。我们这里主要介绍一个叫 Minerva 这样的一个大语言模型网络,它是基于 PaLM 设计的,可以看到它在基于通用自然语言数据的训练基础上,还实现了在数学网页以及 ArXiv 数据集上的进一步的训练,这些训练就使得它在数学问题的解上面具有着很强的能力,它可以实现像左边这个证明问题,这样的证明问题需要被分解成若干个步骤完成。Minerva在这个数据集上实现了78.5%的精度,而现在的 SOTA 已经达到了82.3%的一个精度水平。
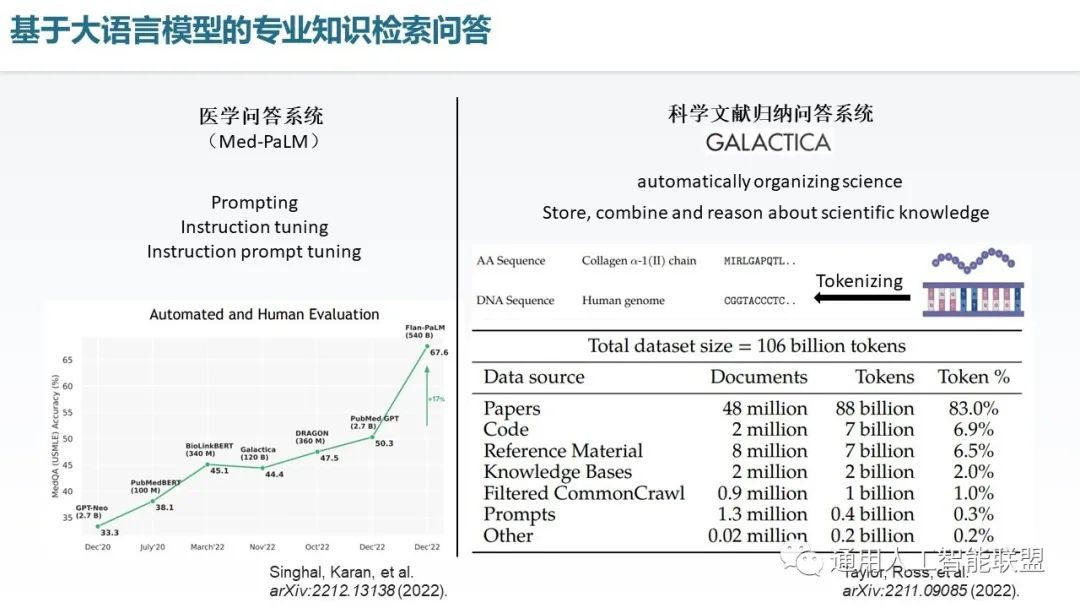
在专业知识检索问答这个方面,Med-PaLM可以实现接近人类水平的医学问题处理,它基于PaLM大语言模型并通过提示,指令微调,指令提示微调这三个技术实现了对于这个应用领域的医学问答的回答质量的显著提升。另外在科学领域 Galactica这个大语言模型是基于 paper 和code以及相关的一些科学领域素材训练出的一个超大规模语言模型,它实现了对于各种科学领域的一个统一的 tokenizing,也就是说可以把各种的文本公式甚至 DNA 序列都编成统一的 token 形态,并进行大语言模型训练,从而实现对于科学文献的归纳总结、推理及问题回答的能力。
在大语言模型机器人任务处理和具身智能方面,Google提出了SayCan方法,提出了将大语言模型与可受性价值评估模型相结合,从而让大模型适配于机器人的真实作业环境的方法。其中大语言模型用于将自然语言指令转化为一系列微指令及评分,但这些微指令并不能保证适配于机器人的当前环境和状态,因此又引入了价值评估函数,用于实现微指令与当前环境的适配度评分。将两者的评分结合(相乘),就实现了智能体既能听从自然语言指令,并适应实际环境且指令具有可操作性,是大语言模型+增强学习系统在机器人场景适配的一个典型展示。具体的运行流程如右图所示,机器人作业分成若干步骤进行,每步都将自然语言指令本身,以前所有步骤的执行指令作为提示部分,用于引导机器人产生当前指令及评分,语言模型产生的一系列指令通过Value function实现可受性的一个评分,两个评分相乘得到总评分,取评分最高作为执行指令。其中增强学习用于实现Value function的训练。

这个算法需要执行很多步骤,直到获得done,代表执行完毕。在实验中,我们可以看到如右图所示的机器人执行多个复杂子步骤,执行了多次去不同地点,取东西,放东西等操作,为主人拿到饮料和小吃的过程。

基于大语言模型还有一个非常重要的领域,就是 Program Synthesize,Program Synthesize 是让程序自己写程序,或者叫让模型自己写程序的一类方式。最为典型的一个工作是Codex, Codex 是基于GPT-3 训练的,目前也在GPT-3.5上具有一些演进版本。Codex 在他当时的版本中使用了5400万 Github 的代码仓库,合计100多个G的代码样本进行了训练,最后在 Human Eval 数据集上实现了多样本可试错的情况下77%的成功率,是里程碑的一个成果。可以实现例如右图这样一个语言描述转python代码,或者描述加例子转代码的这样的一些代码生成工作。

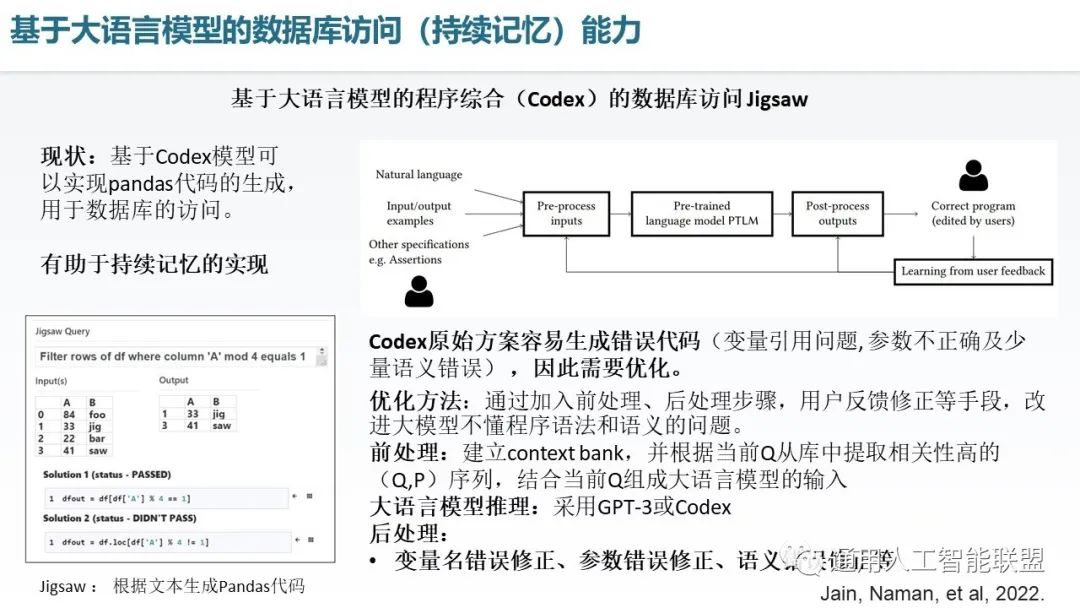
我们可以将大语言模型的代码生成能力应用于对数据库的访问和对表格的访问上面,Jigsaw 这个工作就是基于 Codex 模型衍生的,可以实现Pandas 代码生成,这个工作有助于未来的持续记忆的实现,由于Pandas 的这个操作代码表格的能力和数据库的能力实际上是对这种声明式长期记忆数据的一个管理、索引以及存储的能力,因此我们可以将 Codex 作为一个驱动器去驱动我们的长期记忆体,这个长期记忆体是基于数据库或表格来存储信息的。Jigsaw在做这件事的时候呢也发现 Codex 的原始生成代码经常容易出错,因此也进行了相关优化,包括建立了一些Context Bank 做前处理,那这个 Context Bank包含了诸多Query,Program 例子对的序列作为few shot的素材,之后从当前的 Query 库中提取相关性高的例子,用于提升当前query的回复精准度。另外,通过大模型生成的代码又进行了后处理,包括变量名修正,参数错误及语义错误的修正,从而让产生的代码更正确。
此外大语言模型程序生成的另一个应用是数学问题求解。它通过Codex生成数学问题的解题程序,并通过计算机运行程序获取解,相当于给智能体配置了一台计算机去做复杂的计算,用来实现数学解题。此外呢,它还可以对生成的代码进行一定的解释。在 MIT 和哥伦比亚大学的多项数学课程上以及多项 MATH数据集的Topics上进行了验证,达到了非常好的效果,实现了整体上81%的解题率。

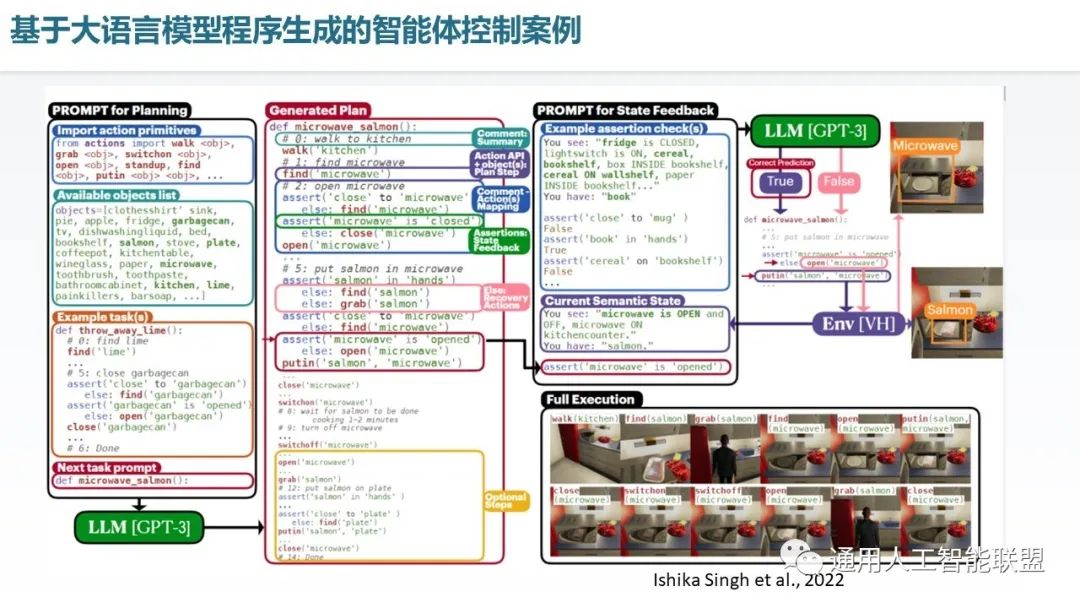
另外基于大语言模型的程序生成技术还可以实现家庭场景下的智能体控制。在这个例子里呢,其主体是基于 GPT-3 的大语言模型,在这个基础上,先通过提供相应的背景环境信息,或者叫变量信息,之后提供一些例子作为代码生成的可学习的样本,之后是我们希望生成的智能体控制的定义的函数名称,之后输入给大模型,就会生成相应的这个任务函数的执行过程代码,代码中还通过assertion根据这个当前环境是否满足了预期进行相应的判断,并对不满足预期时候的这个行为通过补偿处理机制处理, 实现了与环境闭环交互,对于像这样一个家庭的智能机器人的场景,实现了典型任务下的智能体控制。
基于Transformer还可以实现程序的执行过程,就像处理器可以执行程序一样,只是这回是通过神经网络来执行程序,它相对于纯程序执行具有非结构化和模糊化执行的能力。可以实现对程序-图片对这种VQA任务的处理,以及策略执行的细化。对于VQA来讲,它可以实现这个指令和这个图像的相互交互的过程,对于这个策略执行细化而言,可以实现对于宏观目标的一个执行过程的细化。我们以Program Guided Transformer,即Proto来举例。这个例子中首先具有一个程序指针更新函数,这个程序指针用于指示它在哪一个步骤被执行,并且决定下一步是继续执行这个步骤,还是跳转到下一个步骤。然后在这个程序指针外部有一个执行循环,这个执行循环具有进行推理和指针更新两个子阶段。那么这个网络结构就有点像一个处理器一样,可以把这个程序执行下来。它的基础结构是三层的Cross-Attention的一个Transformer Layer的形态,首先,实现的是语义的注意力,这个语义包括函数(如select),以及参数(如bag)。第二个注意力是代码依赖结构,就是说当前语句跟哪些程序语句的执行结果有连接,那么就用一个相关度的一个度量矩阵的一行,把它们的关联关系表达出来。最后还有一个关于场景信息的融合,用于处理图像和地图这样的数据。经过这三层注意力,就实现了一个具有程序执行功能的神经网络。

最后,我们也测试了一下ChatGPT的元技能组合能力,在此我们对MIPS的汇编语言指令集进行了一定的修改,用汉语拼音修改了一部分指令,如load替换成了jiazai,save变成了baocun,两者不等则跳转的jne改写为tiaobudeng等等,但保留了每个指令的含义解释。因此我们构建了一个简单的新的指令集,也可以理解成元技能集,在此之上,我们测试大语言聊天模型ChatGPT,让它基于这个指令集编写一段阶乘的代码,编写的代码如右侧所示。经目测整体逻辑是正确的,但目前这个实验会有很大的方差,有时会生成不一样且不对的代码,而且不太容易纠正。因此我们可以认为目前大语言模型在这个领域有潜力,但仍需要进一步稳定水平和提升水平。

综上所述通用大模型的逻辑认知状态可以总结为以下几点,首先在优势上面,大语言模型可以利用海量的人类的文本信息进行训练,第二,当前大模型在很多地方也确实超过了人类的水平,或者逼近了人类的水平,第三,它可以具有一定的逻辑推理能力,包括常识、事件、隐式推理等等,第四,它还具有着一定的代码生成能力和代码解释能力,最后,它还具有强生成和强创造特性,在AIGC的最近的领域里都有所表现,
但是它也具有着若干的不足与挑战,包括仍不能算作一个完整的认知框架,它还缺乏长期记忆、情境记忆,以及模型个性化,或者说它记不住自己以前做过的事情。另外它是基于有限上下文的输出,对于长程写作的或者长程的逻辑推理,仍然是稍显不足。另外,对于真实世界的交互还不太充足,包括认知感知之间的结合不紧密,此外,就是目前的逻辑还是以文本作为基础的。另外,影响它发展的一个重要因素就是训练代价比较高,通常,使用者缺乏持续模型更新的一个能力,这个模型训练出来之后基本上是不能修改的,研发成本也高,使用成本也不低,所以导致的就是能玩得起的人也比较少。

大模型从一定层面上可以看作是认知架构的一种具体实现,具有强认知能力,是当前最火热的学术领域之一,不过大多数分析仍然从人工智能内容生成(AIGC)、多模态、自然语言处理的角度去理解它,而没有从强智能的里程碑的意义的角度去理解它,是有所缺失的。本文重点关注的是它对于逻辑推理认知、精确的可解释的输出(程序)、实现机器人任务的潜在能力,个人认为这些能力比陪聊或者作画可能更能激起未来发展的浪潮。它可以说是发展了40余的认知架构的最大革新。此外,结合它的多模态特性,有望作为通用基础模型(foundation model),我们在最后一期分享中讨论它的后期演进。本期分享就到这里,下期我们将关注学习技术。

